What Is Robots.Txt & Why It Matters for SEO

Robots.Txt file is a significant component of any website that can make or break its visibility on search engines.
A critical procedure named crawling must be completed before your website gets the spotlight of top search engine rankings.
Website crawling is search engine bots’ journey to discover and index web pages.
These bots, often known as “web crawlers” or “spiders,” are the unsung internet heroes that meticulously crawl the enormous web, classifying and indexing web pages so that they may be quickly found when users make searches.
Getting web pages indexed is a crucial process that Robots.
Txt files manage by directing web crawlers.
What Is Robots.txt?
A robots.txt file is a text file stored on a website’s server and provides instructions for web crawlers on which page to access and which not to interact with on the website.
This is mostly intended to prevent your website from becoming overloaded with queries.
However, it is not a method of keeping certain website pages from Google.
Use “noindex” to prevent indexing of a page or password-protect it to prevent Google from finding it.
It safeguards private data, improves SEO strategies, controls server resources, and ensures search engines effectively index their material.
Still, Robots.txt should be used carefully and appropriately since incorrect setups may unintentionally prevent critical material from being indexed by search engines or result in other unwanted problems.
Importance of Robots.txt in SEO
Concerning how the Robots.txt file help helps website owners manage how search engine crawlers access and index their site, here is why robots.txt is so important in SEO –
1. Optimize Crawl Budget
Crawl budget refers to the number of pages search engine crawlers crawl on your website.
By optimizing it, you can make sure people pay attention to your most crucial material.
Robots.txt directs search engines to prioritize important pages, prevent unnecessary crawling, and concentrate on new content. It improves the indexing of important information, lessens server load, and effectively uses crawl resources are all advantages.
2. Block Duplicate and Non-Public Pages
Duplicate and private material might hurt a website’s SEO.
Search engines might become confused by duplicate material, and private content shouldn’t be indexed.
Robots.txt’s function is to prevent search engines from indexing confidential pages by blocking duplicate content and sensitive portions of the website.
It improves On-site SEO by eliminating duplicate content and maintain security and privacy
3. Prevent Indexing of Resources
Search engines should index web pages rather than specific resources like scripts, PDFs, or graphics. Resources can be inefficiently indexed.
Robots.txt instructs search engines to concentrate on the primary content by forbidding the crawling of non-HTML resources like photos and scripts.
It improves the crawl budget’s effective use, preventing duplicate picture indexing and faster page loads for enhanced SEO.
Robots.txt files that are properly designed ensure that search engines prioritize your most crucial content, maintain the standard of indexed pages, and improve your website’s overall SEO performance.
The Basics of Robots.txt
A robots.txt file looks like the below image –

Basic terminologies used with Robots.txt file are as follows –
- User-Agent Directive: This parameter defines which web crawler or user agent the rules apply to. Each bot and search engine has a unique user-agent name.
For instance, the user agent for Google’s web crawler is Googlebot. If necessary, you can develop unique rules for each user agent.
- Disallow Directive: The “Disallow” directive instructs the web crawler to avoid certain areas of your website. You designate folders or URLs you don’t want search engines to index.
For instance, you may use “Disallow: /” to block everything if you don’t want a bot to crawl the whole site. Use “Disallow: /private/” to ban a specific directory if you wish to.
- Allow Directive: The “Allow” directive can override a “Disallow” rule. When a more general “Disallow” rule is in effect, it determines which areas of the website may be crawled.
You may, for example, provide access to a certain folder while preventing a user agent from crawling the whole of your website.
- Sitemap Directive: The “Sitemap” directive tells search engine crawlers where your XML sitemap(s) are located. A structured file called an XML sitemap in SEO contains a list of all the URLs on your website that need to be scanned and indexed.
The effectiveness of crawling and indexing can be increased by including this directive.
- Crawl Delay: Although this directive is not frequently used, it indicates the time (in seconds) that should pass between queries made to your server by a web crawler.
For instance, “Crawl-Delay: 10” might instruct the crawler to delay making queries by 10 seconds.
It is also essential to regularly check and update your robots.txt file to make sure it accomplishes what you want it to.
How Does a Robots.txt File Work?
A robots.txt file instructs search engine crawlers which URLs they may explore and, more critically, which ones they should ignore. Search engines rely on following links from one website to another through millions of domains to scan the web to find information, index, and provide content to users.
Search engine bots continually crawl web pages by clicking links from one website to another.
When a bot first visits a new website, it checks the root directory for a robots.txt file.
When a robots.txt file is found, the search engine bot will read it before doing other tasks on the website.
The robots.txt file has simple syntax and organization.
The user agent identifies the search engine bot to whom the rules should apply and is initially identified before rules are assigned.
The directives (rules), which define which URLs the detected user-agent should crawl or ignore, are given after the user-agent.
For example, a robots.txt file might include the following directives –
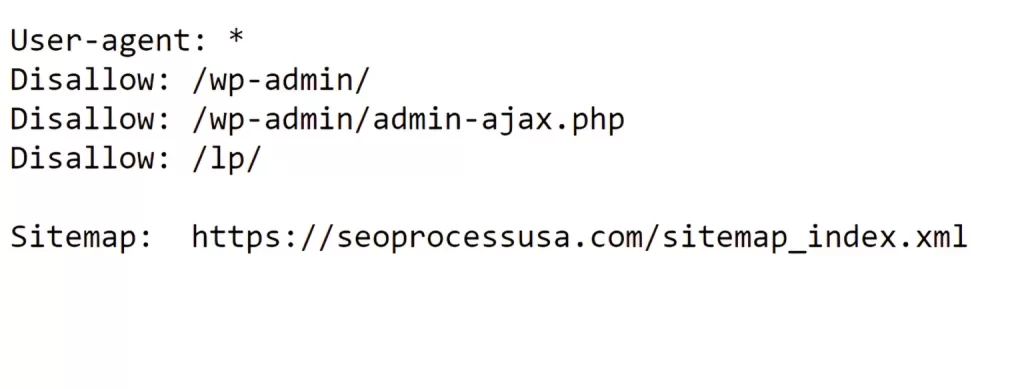
Remember that a robots.txt file solely provides instructions; it cannot enforce them.
Search engine bots follow the robots.txt file’s regulations, including those employed by respectable search engines like Google. However, like spam bots, hostile or “bad” bots may disregard these guidelines and continue to crawl the page.
Benefits of Optimizing Robots.txt for SEO
Optimizing robots.txt file for SEO offers several benefits that can improve a website’s search engine exposure and general performance.
1. Enhancing site crawl efficiency
You may improve the effectiveness of search engine crawling by optimizing your robots.txt file to point crawlers to the most crucial and pertinent areas of your website.
Search engine bots will use their crawl budget wisely if you define what information should be scanned and indexed and which should be omitted.
This enables them to concentrate on indexing useful content while ignoring irrelevant or low-priority sites, eventually resulting in a more effective crawl.
2. Controlling which content appears in search results
Controlling which pages and areas of your website appear in SERPs is easier with a well-configured robots.txt file.
You may stop information you don’t want to show up in search results from being indexed and shown by search engines by restricting access to specific locations. This control ensures that the text displayed in SERPs adheres to your branding and SEO goals.
3. Allowing/disallowing specific crawlers
You may designate which user agents or web crawlers are permitted or prohibited from accessing your website using robots.txt.
This degree of control is useful for customizing your SEO plan. You could wish to enable Googlebot but block some obscure crawlers, for example.
Alternatively, you may allow some crawlers access for particular uses like site audits or monitoring while preventing access to others.
4. Managing duplicate content through robots.txt
Duplicate content problems, which can harm SEO by puzzling search engines and affecting ranks, can be resolved with robots.txt.
Access to duplicate material, such as printer-friendly pages, archival information, or URL session IDs, might be restricted.
By doing this, you may enhance SEO results and avoid potential fines for duplicate content since you stop search engines from indexing numerous versions of the same material.
An optimized robots.txt file improves search engine rankings and user experience by ensuring that search engines index your website in a way that is consistent with your SEO strategy and maximizes your online exposure.
Best Practices for Robots.txt and SEO
Here are the best practices to use robots.txt in SEO –
1. Use New Lines for Each Directive
The robots.txt file is simpler to maintain and comprehend with proper formatting that uses new lines. For clarity, each instruction has to be separated.
To increase readability and guarantee that web crawlers appropriately translate user-agent directives, separate each user-agent directive (User-agent, Disallow, Allow, etc.) on a different line.
Incorrect

Correct

2. Use Each User-Agent Once
Multiple listings for the same user agent may confuse and cause it to act differently than intended. Grouping rules under a single-user agent directive is simpler and more effective.
Do not repeatedly specify the same user agent.
The user-agent directive should be stated once, followed by a list of all applicable rules for that user agent.
Incorrect

Correct

3. Use Wildcards to Clarify Directions
Using wildcards, you may build more comprehensive rules without mentioning every URL one by one.
They can make creating and maintaining rules simpler.
When necessary, provide patterns using wildcards (*). To prevent access to all JPEG pictures in the “images” directory, use the command Disallow: /images/*.jpg.
Incorrect

Correct

4. Use ‘$’ to Indicate the End of a URL
Using a dollar sign (‘$’), you may guarantee that the rule matches the URL, eliminating the unintentional banning of URLs with identical patterns.
An exact match is denoted by the dollar symbol ($) at the end of a URL. Use the command Disallow: /login$, for instance, to block only the “/login” page.
Incorrect

Correct

5. Use the Hash (#) to Add Comments
Comments aid in the robots.txt file’s documentation and make it simpler for others (including yourself) to comprehend the goals of particular directives.
Use the ‘#’ Sign in your comments to add context or clarify the rules’ purpose.

6. Use Separate Robots.txt Files for Different Subdomains
Use several robots.txt files for each subdomain if you have several subdomains with different rules.
This strategy enables you to individually customize rules for each subdomain, ensuring that content is accurately indexed for each subdomain.
7. Prioritizing important pages for indexing
Use robots.txt to guide search engine crawlers toward the most important pages of your website by allowing them access to critical content.
Giving access to high-priority information ensures that search engines index these pages first, which can help your SEO efforts.
8. Handling dynamically generated content
Use robots.txt with caution when attempting to prevent dynamically created material.
Prevent unintentional blocking of crucial material produced by JavaScript or other technologies.
Client-side rendering and dynamic content loading are often used in contemporary websites.
To preserve SEO exposure, make sure that search engines can access and index vital material produced dynamically.
These practices will help you manage your robots.txt file well and efficiently, improve SEO, and ensure that search engines crawl and index your website to support your objectives.
Common Mistakes of the robots.txt File and Ways to Avoid Them
Here are some common mistakes of robots.txt files and ways to avoid them to ensure search engine crawlers properly interpret your directives –
1. Not placing the file in the root directory
Search engine bots may be unable to read or follow your robots.txt instructions if you place the file in the wrong directory or root directory, which might result in unintentional content indexing or blocking of important pages.

2. Improper use of wildcards
The incorrect usage of wildcards, such as ‘*’ or ‘$,’ may result in URLs being accidentally blocked or allowed.
Wildcards used incorrectly may provide instructions that are unclear and incoherent.
Unnecessarily used wildcards can block the entire folder instead of a single URL.

3. Using the NoIndex directive in robots.txt
The “NoIndex” directive in robots.txt is invalid and is not interpreted by search engine bots after Google announced that it will not work in robots.txt files from September 1, 2019. Utilizing it could result in unproductive SEO techniques.
Incorrect approach

Correct approach
Using meta robots tag.

4. Unnecessary use of trailing slash
Misused trailing slash for blocking or allowing a URL in robots.txt is a common mistake.
For example, if you want to block a URL https://www.example1.com/category with the following directives, it can lead to big trouble.

It will instruct website crawlers not to crawl URLs inside the “/category/” folder instead of blocking the URL example.com/category.
The right way to do this is –

5. Not mentioning the sitemap URL
The ability of search engine bots to find and properly index your website might be troubled if your sitemap’s location is not included in your robots.txt file.
Declare your sitemap using the following command and remember to submit the sitemap to google.
Sitemap: https://www.example.com/sitemap.xml
6. Blocking CSS and JS
It is a common mistake that most people make thinking Googlebot indexes CSS and JS files.
However, Google crawlers don’t do this.
Blocking search engines from accessing your site’s CSS and JavaScript files can hinder their ability to render and understand your web pages correctly, impacting SEO and user experience.
Ignoring case sensitivity
Robots.txt directives are case-sensitive. Ignoring case sensitivity can lead to incorrect rule interpretation by search engine crawlers.
Incorrect approach

Correct approach

These are some common mistakes people make with robots.txt files, which can drastically harm their SEO efforts.
Monitoring and Testing Robots.txt
Testing for a Robots.txt file begins with determining whether it is publicly accessible or uploaded properly.
For this, open a private window in a browser and search for your robots.txt file.
For example, https://semrush.com/robots.txt
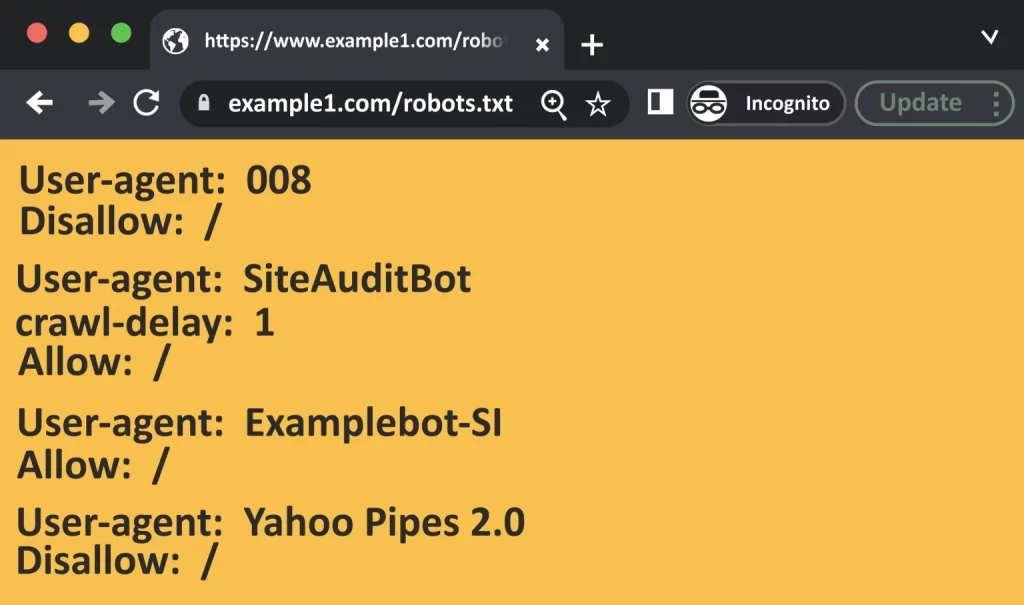
This test is clear if you can see your website’s robots.txt file, as shown above.
Next is the markup (HTML code) test. You can perform it using tools like robots.txt Tester in Search Console, Google’s open-source robots.txt library, and website audit tools like SEMrush’s Site Audit.
If you have a Google Search Console account, use robots.txt Tester to test the website’s robots.txt file.
- Open the Robots.txt Tester tool through Google Search Console.
- In the tool, you’ll see your robots.txt file. Look for any highlighted syntax warnings or logic errors below the editor.
- In the text box at the bottom, enter the URL of a page on your website that you want to test.
- Select the user agent (search engine bot) you want to simulate from the dropdown list next to the URL box.
- Click the “TEST” button to see if the URL is “ACCEPTED” or “BLOCKED” based on your robots.txt rules.
- Review the test result to see if the URL is allowed or blocked for the chosen user-agent.
- If the result is unexpected, click the “Edit” button within the tool to make changes to your robots.txt file.
Remember, changes here don’t affect your live site.
- Once satisfied with the edits, copy the changes to your robots.txt file on your website. The tool doesn’t make changes to your site; it’s for testing only.
- After updating your robots.txt file, run additional tests, perform a website audit for SEO, and monitor search engine crawling to ensure your website’s desired access rules are followed.
Similarly, you can also use SEMrush’s Site Audit tool to test your robots.txt file and monitor its performance.
Robots.txt vs. Meta Robots Tag
There are two ways to manage how search engines scan and index online content: robots.txt and the meta robots tag.
Each has a special function and is applied in various circumstances.
| Aspect | Robots.txt | Meta Robots Tag |
|---|---|---|
| Location | Placed in the root directory of a website | Placed within the HTML code of individual web pages |
| Function | Provides instructions to search engine crawlers about which parts of a website they are allowed to crawl and index and which parts they should avoid | Provides page-level instructions to search engines on how to treat that specific webpage |
| Scope | Website-wide instructions | Page-specific instructions |
| User-Agent Specific | Yes, allows customization for different user agents (search engine bots) | No, applies to the specific webpage it’s placed on |
| Crawl Guidance | Guides crawlers efficiently by indicating which pages or directories should be crawled or ignored | Controls indexing and following behavior at the page level |
| Blocking URLs | Can block entire directories or specific URLs from being indexed | Controls whether a specific webpage should be indexed, followed, or omitted from search engine results |
| Granular Control | Broad directives affecting multiple pages and directories | Detailed control for specific pages |
| Customization | Customizable for different search engines or user agents | Uniform across all search engines |
| Content Rendering | Does not affect how content is rendered or displayed to users | Does not affect how content is rendered or displayed to users |
| Flexibility | More suitable for broad, site-wide directives | It is ideal for customizing behavior on a per-page basis |
Final Words
The robots.txt file may appear to be a minor and frequently forgotten component of website handling, yet its importance to SEO cannot be overstated.
Robots.txt also helps to improve the website’s search engine visibility, user experience and ultimately get better SEO results by learning how to use it properly and avoiding common pitfalls. Mastering the robots.txt file is a critical step toward SEO success in the ever-changing field of digital marketing.
FAQs:
1. What is robotics in SEO?
The use of rules and directives, often stated in a robots.txt file, to advise search engine crawlers on accessing and indexing a website’s content is called robotics in SEO.
It is critical in determining how search engines interact with a website for SEO purposes.
2.What does a robots.txt file facilitate in the content phase of SEO?
A robots.txt file aids in regulating search engine crawling and indexing throughout the content phase of SEO.
It aids in determining which portions of a website should be scanned and indexed by search engines and which should be banned.
This guarantees that useful material is prioritized while irrelevant or sensitive stuff is not indexed.
3. What is required for robot.txt?
A text editor like Notepad and access to the root directory of your website are required to generate a robots.txt file.
You may manually write the directives to control search engine bot activity or utilize generating tools to help you create the file.
4. What is the size limit for robots.txt file?
A robots.txt file has no fixed size restriction.
However, it is advised that the file be kept brief and that excessive regulations be avoided.
Website owners should strive for an appropriate file size to ensure search engine crawlers can digest it efficiently.
5. Is a robots.txt file necessary?
While a robots.txt file is not required, it is strongly recommended for SEO purposes.
It enables website admins to send clear instructions to search engine crawlers, maximizing crawl budget, avoiding sensitive information from being indexed, and enhancing overall search engine exposure.
Using a robots.txt file is a great practice for good website administration and SEO.